Our CertBlaster® test prep software is AWESOME! Exactly how awesome you may ask? Well, awesome enough that we offer an exceptional 6-month First Try Guarantee on all our CertBlaster® practice tests. ALL of them! If for some inexplicable reason, you would fail, then we’ll give you a full, no-hassle refund. That’s how confident we are that CertBlaster® will get you ready.
This video showcases the main features you will benefit from when preparing for your IT certification with the CertBlaster Exam Simulator. CertBlaster replicates the exam experience for IT engineering certification tracks with a focus on CompTIA, Microsoft, and Linux Professional Institute.
All of our online courses include practice tests which include questions and formats that you will find on the exams. What better way to get prepared than to actually take practice exams in order to determine areas where you might need to focus on further as well as to get yourself mentally prepared to be in the test taking environment.
Even better, you’re able to do this all from the comfort of your own home! Take control, prepare, and level up in your career by getting these certifications.
Some of our most popular practice tests are as follows:
Since 2001 CertBlaster® has helped in excess of a million users prepare for their CompTIA certification exams. Year after year we add features, narrow our focus on the features that truly help our users and expand those capabilities and refine our approach. For starters though, we make sure we simply have a vast number of test prep questions – which is critical to your study and preparation. In addition to that find below a list of the major benefits CertBlaster brings to your exam preparation:
Exam-like
Questions matching each and every exam objective and sub-objective. Answers with detailed explanations.
Assessment Mode
That, upon completion, will prepare your custom Personal Testing Plan (PTP) with a list of items to study just for you.
Certification Mode
Is the actual CompTIA exam simulation, the timer is set for the exam time, same type and number of questions as the exam and same distribution of questions per exam objective as the exam. This is like taking the exam from the comfort of your home! It will do wonders to you time management skills in preparation for the actual exam and help you avoid running out of time unexpectedly on the exam.
Study Mode
Here you can see all answers and all explanations to study and improve your knowledge base on the same type of questions you will see on the exam.
Focus drills
One drill per exam objective, these practice tests help you practice one main exam objective at the time because all the questions in these drills are exclusively focused on one exam objective.
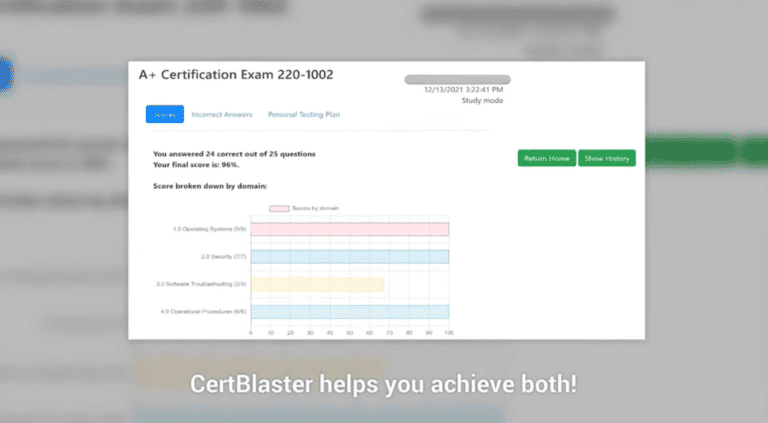
A detailed score report
Helps you Identify what you already know and what you need to study more. With overall scoring as well as per objective scoring you will rapidly know where you need to focus.
Custom tests
based on your performance, after any of our Focus Drills or Exam simulations, CertBlaster will offer you the option to make on the fly a test just for you that will focus only on your weak points.
An exceptional Test Pass Guarantee
Our First Try Guarantee, because an exam voucher costs too much for you to want to pay it twice.
By continuing to browse this site, you accept the use of cookies and similar technologies that will allow the use of your data by CertBlaster in order to produce audience statistics- see our privacy policy.